방대한 PDF 문서 GraphRAG PoC사례
Nayeon Park
·

안녕하세요 AI Engineer 박나연입니다.
방대한 PDF 문서를 대상으로 한 GraphRAG 사례를 설명드리겠습니다.
퓨처워크랩은 H사의 방대한 PDF 문서를 대상으로, 이런 비정형 문서 간의 연결 관계를 구조적으로 표현하기 위한 PoC를 진행했습니다. 이를 위해 문서 속 개념을 그래프 형태로 구조화하고, 문서 간 관계를 연결해주 GraphRAG 기반 문서 검색 PoC를 진행했습니다.
문서의 구조화
고객사에서는 기본적으로 문서의 계층 구조를 유지하기를 원했습니다. 이를 통해 긴 분량의 문서도 체계적으로 관리하고자 했습니다. 이를 위해 어떤 내용의 문서가 들어와도 그 속에서 목차 패턴을 찾아내 목차의 계층 구조를 추출해야 했습니다. 이를 해결하기 위해, 퓨처워크랩의 솔루션은 PDF 문서 내에서 목차 구조를 자동으로 추출하고 이를 그래프화 하는 기능을 탑재했습니다.
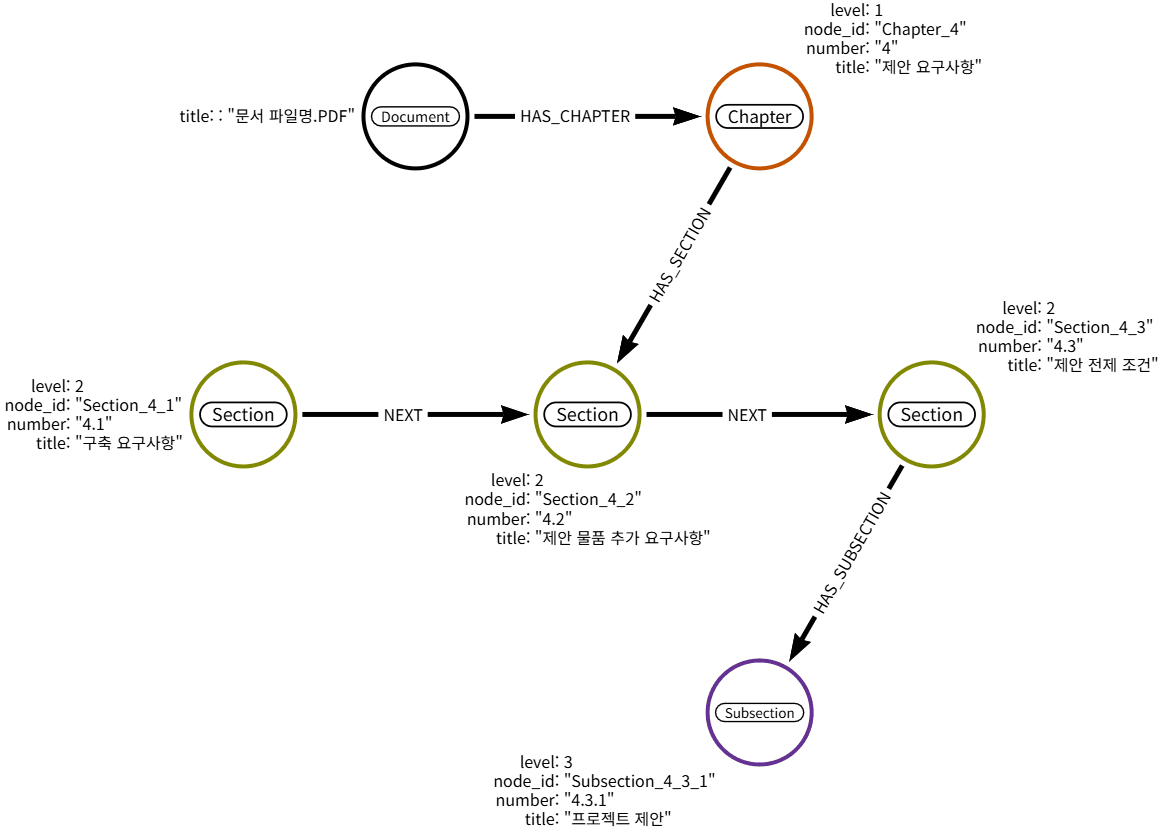
[그림3]은 실제 PoC에 진행한 PDF 문서 내의 목차 구조를 추출해 그래프화 시킨 모습입니다. 문서는 Chapter → Section → Subsection의 목차 구조를 가지고 있으며, 목차를 구분하는 텍스트에서의 패턴을 찾아내 그래프화할 수 있습니다.
문서의 기본 정보에 대한 검색
퓨처워크랩은 단순히 데이터를 그래프 DB에 저장하는 것을 넘어, 이를 직관적으로 탐색하고 질문할 수 있는 시스템을 구축했습니다. 이때 사용한 GraphRAG 검색 방법의 종류를 2가지 소개해드리려 합니다.
Text2Cypher는 사용자의 질문을 Cypher 쿼리로 변환하는 것을 의미합니다. 주어진 그래프 DB 스키마 정보를 기반으로 쿼리를 생성하게 되므로, 미리 정의된 엔티티 라벨과 프로퍼티, 관계를 통해 검색이 가능한 경우에 사용합니다.
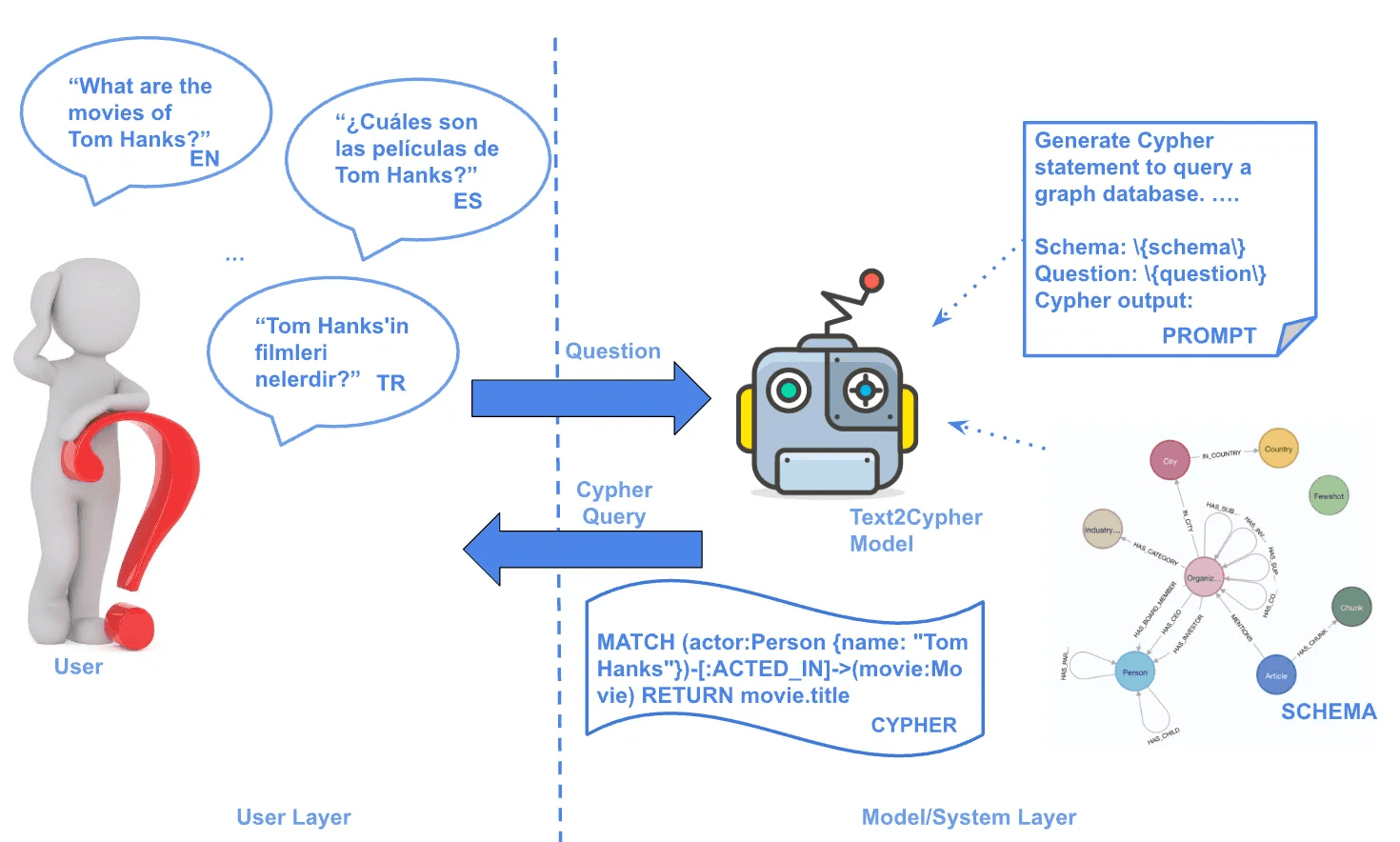
본 PoC 프로젝트는 PDF 문서를 그래프로 변환하여 사용했으며, 위와 같이 기본적으로 문서 및 목차를 나타내는 노드, 엣지를 가지고 있습니다. 따라서, 다음과 같은 정의된 노드 라벨과 프로퍼티에 맞게 문서의 구조를 물어보는 질문에 대한 대응에 적합합니다.
🧑 어떤 문서가 저장되어 있나요?
QUERY: MATCH (d:Document) RETURN d.title, d.type
🧑 문서의 목차를 알려주세요.
QUERY: MATCH (c:Chapter) RETURN c.number, c.title ORDER BY c.number LIMIT 10
위 예시처럼 생성된 쿼리로 DB에 조회할 수 있습니다. 이를 통해 사용자는 체계적이고 구조화된 신뢰 가능한 데이터를 기반으로 정보를 확인할 수 있습니다.
문서의 기본 정보에 대한 질의응답
문서 PDF에서는 목차 구조뿐 아니라 실제 텍스트 원문 또한 저장해야 했는데요. 퓨처워크랩은 이를 위해 관련있는 텍스트를 검색하고 주위의 맥락도 함께 검색할 수 있는 VectoreCypher 검색 방식 또한 활용했습니다.
VectorCypher는 벡터 기반의 의미검색과 Cypher 쿼리 기반 검색을 합친 방식입니다. 이는 의미 기반의 내용 검색을 기반으로 답변이 필요한 경우에 사용할 수 있습니다. VectorCypher가 일반 벡터 검색과 다른 점은 벡터 검색 수행 후, 그 주변에 연결된 그래프 검색까지 함께 수행한다는 점인데요. 그렇기 때문에 단순히 벡터 청크 안에서만 정보를 찾는 것이 아닌, 그것과 연결된 맥락(문서의 목차 정보, 관련 엔티티 등)까지 함께 검색이 가능합니다.
[그림 5] 문서 내 텍스트 원문 및 엔티티 정보 그래프
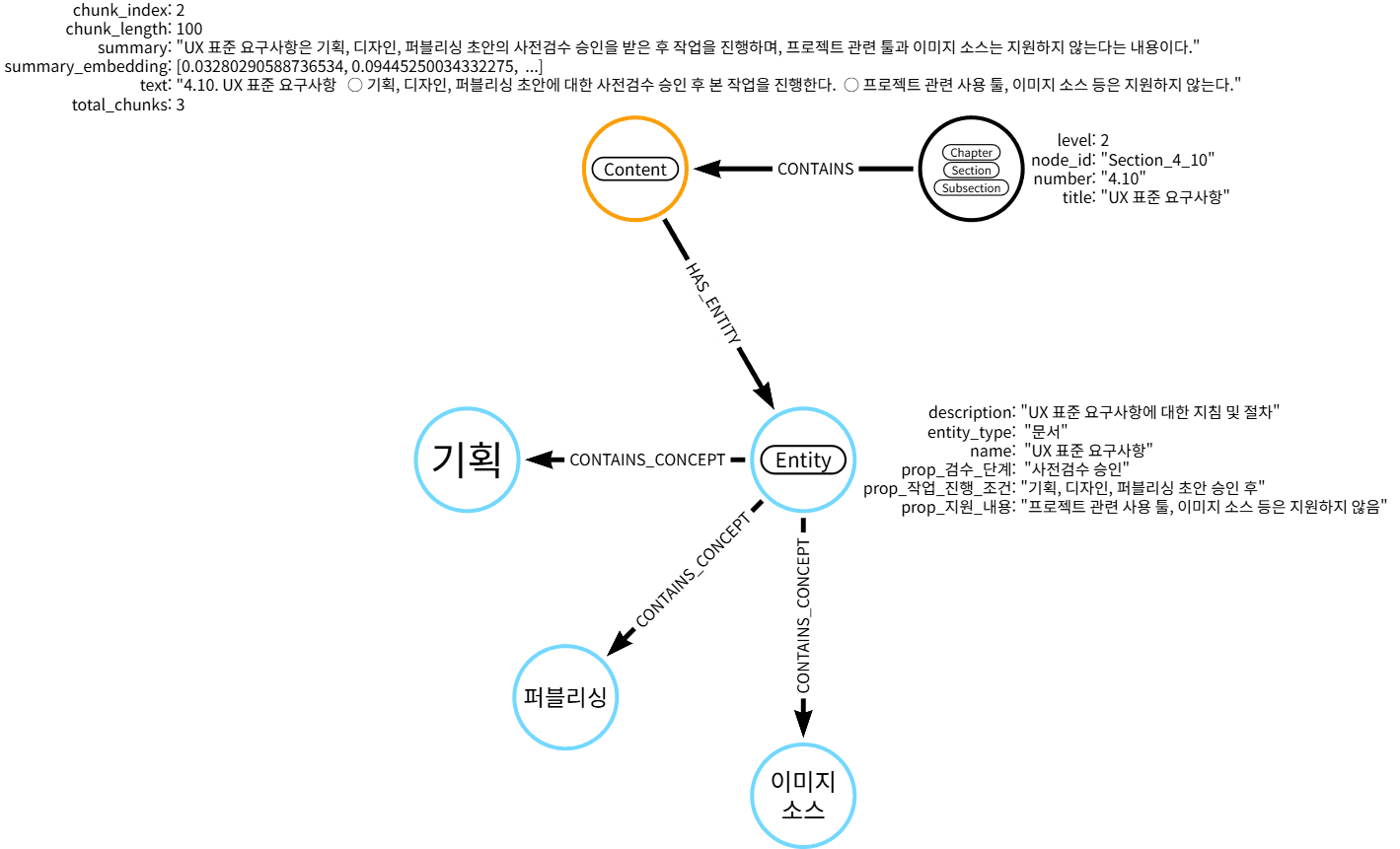
[그림 5] 문서 내 텍스트 원문 및 엔티티 정보 그래프
본 PoC에 사용한 PDF 문서에서, 각 목차에 포함된 텍스트 정보를 Content 노드로 표현했습니다. Content 노드에는 텍스트 원문이, 그리고 그 텍스트에 등장하는 핵심 엔티티 정보를 수집하고 있습니다. 이때, 만약 관련된 정보를 찾고 싶다면 Content 노드에서 summary 프로퍼티를 기준으로 벡터 검색을 수행하도록 하고, Content와 연결된 주변 엔티티를 추출하기 위해 탐색 쿼리(retrieval query)를 사용할 수 있습니다.
쿼리를 통해 크게 3가지 정보를 추출합니다.
벡터 검색으로 추출된 노드 자체의 정보 추출
node.text AS content_raw_text, node.summary AS content_summary, → 관련 내용이 포함된 Content 노드의 원본 텍스트와 요약 텍스트를 추출
벡터 검색으로 추출된 노드의 목차 정보 추출
MATCH (node)<-[:CONTAINS]-(c) RETURN c.node_id AS chapter_id, c.number AS chapter_number, c.title AS chapter_title,
벡터 검색으로 추출된 노드 주변에 연결된 엔티티 정보 추출
collect(DISTINCT { name: entity.name, type: entity.type, description: entity.description }) AS entities, collect(DISTINCT { source_entity: startNode(rel).name, relationship_type: type(rel), target_entity: endNode(rel).name, description: rel.description }) AS entity_relationships → 관련 내용이 포함된 Content 노드와 연결된 Entity 노드의 이름과 설명, 엣지 정보를 추출
이를 통해 벡터 검색을 기반으로 관련있는 내용이 포함된 Content 노드를 찾을 뿐 아니라, 주변에 연결된 목차 정보와 엔티티 정보를 함께 추출하기에 좀 더 풍부한 맥락을 기반으로 답할 수 있게 됩니다. 따라서 아래와 같은 질문에도 대응이 가능합니다.
🧑 UX 표준 요구사항 관련 내용이 포함된 위치를 알려주세요.
🧑 UX 표준 요구사항에는 어떤 지침이 포함되어 있나요.
위 질문 예시의 경우, 벡터 기반으로 관련 내용을 먼저 찾고, 함께 검색된 주변 맥락을 기반으로 답해야하는 경우입니다. “UX 표준 요구사항 관련 내용이 포함된 위치를 알려주세요.” 의 경우, UX 표준 요구사항 관련 내용이 포함된 Content 가 벡터 검색으로 추출될 거고, 이와 함께 검색된 목차 노드를 참고하여 답할 수 있게 됩니다.
물론, 주변 엔티티 정보를 함께 참고할 필요가 없는 내용 기반 질문이라도, 기본 벡터 검색 결과(Content 노드)를 참고하여 답할 수 있습니다.
확인할 수 있는 인사이트
이번 H사 PoC를 통해, 퓨처워크랩은 비정형 문서의 구조적 이해가 단순한 검색 정확도를 넘어, 조직 내 지식 활용 방식 전반을 혁신할 수 있다는 인사이트를 얻었습니다.
문서 간 관계를 시각적으로 ‘이해 가능한 지식망’으로 전환
기존의 키워드 검색은 “문장을 찾는 방식”이었다면, GraphRAG 기반 검색은 문서의 의미적 관계를 탐색하는 방식으로 진화했습니다. 예를 들어, 특정 표준 문서가 어떤 설계 지침, 테스트 프로세스와 연결되어 있는지를 한눈에 파악할 수 있습니다.
문서 구조를 그대로 반영한 ‘신뢰 가능한 검색’ 구현
PDF 내 목차 계층을 그대로 그래프화함으로써, 문서의 문맥을 유지한 검색이 가능해졌습니다. 사용자는 단순히 문장 단위 검색 결과가 아니라, 그 문장이 포함된 챕터·섹션 단위의 맥락까지 함께 이해할 수 있습니다.
의미 기반 검색과 구조 기반 검색의 융합 가능성 확인
VectorCypher를 통해, 단순 벡터 검색으로는 불가능했던 연결 기반 탐색이 가능해졌습니다. 즉, 의미적으로 유사한 문장을 찾을 뿐 아니라, 그 주변의 개념(엔티티)이나 문서 구조를 함께 조회할 수 있어 검색 결과의 신뢰도와 설명력이 향상되었습니다.
안녕하세요 AI Engineer 박나연입니다.
방대한 PDF 문서를 대상으로 한 GraphRAG 사례를 설명드리겠습니다.
퓨처워크랩은 H사의 방대한 PDF 문서를 대상으로, 이런 비정형 문서 간의 연결 관계를 구조적으로 표현하기 위한 PoC를 진행했습니다. 이를 위해 문서 속 개념을 그래프 형태로 구조화하고, 문서 간 관계를 연결해주 GraphRAG 기반 문서 검색 PoC를 진행했습니다.
문서의 구조화
고객사에서는 기본적으로 문서의 계층 구조를 유지하기를 원했습니다. 이를 통해 긴 분량의 문서도 체계적으로 관리하고자 했습니다. 이를 위해 어떤 내용의 문서가 들어와도 그 속에서 목차 패턴을 찾아내 목차의 계층 구조를 추출해야 했습니다. 이를 해결하기 위해, 퓨처워크랩의 솔루션은 PDF 문서 내에서 목차 구조를 자동으로 추출하고 이를 그래프화 하는 기능을 탑재했습니다.
[그림3]은 실제 PoC에 진행한 PDF 문서 내의 목차 구조를 추출해 그래프화 시킨 모습입니다. 문서는 Chapter → Section → Subsection의 목차 구조를 가지고 있으며, 목차를 구분하는 텍스트에서의 패턴을 찾아내 그래프화할 수 있습니다.
문서의 기본 정보에 대한 검색
퓨처워크랩은 단순히 데이터를 그래프 DB에 저장하는 것을 넘어, 이를 직관적으로 탐색하고 질문할 수 있는 시스템을 구축했습니다. 이때 사용한 GraphRAG 검색 방법의 종류를 2가지 소개해드리려 합니다.
Text2Cypher는 사용자의 질문을 Cypher 쿼리로 변환하는 것을 의미합니다. 주어진 그래프 DB 스키마 정보를 기반으로 쿼리를 생성하게 되므로, 미리 정의된 엔티티 라벨과 프로퍼티, 관계를 통해 검색이 가능한 경우에 사용합니다.
본 PoC 프로젝트는 PDF 문서를 그래프로 변환하여 사용했으며, 위와 같이 기본적으로 문서 및 목차를 나타내는 노드, 엣지를 가지고 있습니다. 따라서, 다음과 같은 정의된 노드 라벨과 프로퍼티에 맞게 문서의 구조를 물어보는 질문에 대한 대응에 적합합니다.
🧑 어떤 문서가 저장되어 있나요?
QUERY: MATCH (d:Document) RETURN d.title, d.type
🧑 문서의 목차를 알려주세요.
QUERY: MATCH (c:Chapter) RETURN c.number, c.title ORDER BY c.number LIMIT 10
위 예시처럼 생성된 쿼리로 DB에 조회할 수 있습니다. 이를 통해 사용자는 체계적이고 구조화된 신뢰 가능한 데이터를 기반으로 정보를 확인할 수 있습니다.
문서의 기본 정보에 대한 질의응답
문서 PDF에서는 목차 구조뿐 아니라 실제 텍스트 원문 또한 저장해야 했는데요. 퓨처워크랩은 이를 위해 관련있는 텍스트를 검색하고 주위의 맥락도 함께 검색할 수 있는 VectoreCypher 검색 방식 또한 활용했습니다.
VectorCypher는 벡터 기반의 의미검색과 Cypher 쿼리 기반 검색을 합친 방식입니다. 이는 의미 기반의 내용 검색을 기반으로 답변이 필요한 경우에 사용할 수 있습니다. VectorCypher가 일반 벡터 검색과 다른 점은 벡터 검색 수행 후, 그 주변에 연결된 그래프 검색까지 함께 수행한다는 점인데요. 그렇기 때문에 단순히 벡터 청크 안에서만 정보를 찾는 것이 아닌, 그것과 연결된 맥락(문서의 목차 정보, 관련 엔티티 등)까지 함께 검색이 가능합니다.
[그림 5] 문서 내 텍스트 원문 및 엔티티 정보 그래프
[그림 5] 문서 내 텍스트 원문 및 엔티티 정보 그래프
본 PoC에 사용한 PDF 문서에서, 각 목차에 포함된 텍스트 정보를 Content 노드로 표현했습니다. Content 노드에는 텍스트 원문이, 그리고 그 텍스트에 등장하는 핵심 엔티티 정보를 수집하고 있습니다. 이때, 만약 관련된 정보를 찾고 싶다면 Content 노드에서 summary 프로퍼티를 기준으로 벡터 검색을 수행하도록 하고, Content와 연결된 주변 엔티티를 추출하기 위해 탐색 쿼리(retrieval query)를 사용할 수 있습니다.
쿼리를 통해 크게 3가지 정보를 추출합니다.
벡터 검색으로 추출된 노드 자체의 정보 추출
node.text AS content_raw_text, node.summary AS content_summary, → 관련 내용이 포함된 Content 노드의 원본 텍스트와 요약 텍스트를 추출
벡터 검색으로 추출된 노드의 목차 정보 추출
MATCH (node)<-[:CONTAINS]-(c) RETURN c.node_id AS chapter_id, c.number AS chapter_number, c.title AS chapter_title,
벡터 검색으로 추출된 노드 주변에 연결된 엔티티 정보 추출
collect(DISTINCT { name: entity.name, type: entity.type, description: entity.description }) AS entities, collect(DISTINCT { source_entity: startNode(rel).name, relationship_type: type(rel), target_entity: endNode(rel).name, description: rel.description }) AS entity_relationships → 관련 내용이 포함된 Content 노드와 연결된 Entity 노드의 이름과 설명, 엣지 정보를 추출
이를 통해 벡터 검색을 기반으로 관련있는 내용이 포함된 Content 노드를 찾을 뿐 아니라, 주변에 연결된 목차 정보와 엔티티 정보를 함께 추출하기에 좀 더 풍부한 맥락을 기반으로 답할 수 있게 됩니다. 따라서 아래와 같은 질문에도 대응이 가능합니다.
🧑 UX 표준 요구사항 관련 내용이 포함된 위치를 알려주세요.
🧑 UX 표준 요구사항에는 어떤 지침이 포함되어 있나요.
위 질문 예시의 경우, 벡터 기반으로 관련 내용을 먼저 찾고, 함께 검색된 주변 맥락을 기반으로 답해야하는 경우입니다. “UX 표준 요구사항 관련 내용이 포함된 위치를 알려주세요.” 의 경우, UX 표준 요구사항 관련 내용이 포함된 Content 가 벡터 검색으로 추출될 거고, 이와 함께 검색된 목차 노드를 참고하여 답할 수 있게 됩니다.
물론, 주변 엔티티 정보를 함께 참고할 필요가 없는 내용 기반 질문이라도, 기본 벡터 검색 결과(Content 노드)를 참고하여 답할 수 있습니다.
확인할 수 있는 인사이트
이번 H사 PoC를 통해, 퓨처워크랩은 비정형 문서의 구조적 이해가 단순한 검색 정확도를 넘어, 조직 내 지식 활용 방식 전반을 혁신할 수 있다는 인사이트를 얻었습니다.
문서 간 관계를 시각적으로 ‘이해 가능한 지식망’으로 전환
기존의 키워드 검색은 “문장을 찾는 방식”이었다면, GraphRAG 기반 검색은 문서의 의미적 관계를 탐색하는 방식으로 진화했습니다. 예를 들어, 특정 표준 문서가 어떤 설계 지침, 테스트 프로세스와 연결되어 있는지를 한눈에 파악할 수 있습니다.
문서 구조를 그대로 반영한 ‘신뢰 가능한 검색’ 구현
PDF 내 목차 계층을 그대로 그래프화함으로써, 문서의 문맥을 유지한 검색이 가능해졌습니다. 사용자는 단순히 문장 단위 검색 결과가 아니라, 그 문장이 포함된 챕터·섹션 단위의 맥락까지 함께 이해할 수 있습니다.
의미 기반 검색과 구조 기반 검색의 융합 가능성 확인
VectorCypher를 통해, 단순 벡터 검색으로는 불가능했던 연결 기반 탐색이 가능해졌습니다. 즉, 의미적으로 유사한 문장을 찾을 뿐 아니라, 그 주변의 개념(엔티티)이나 문서 구조를 함께 조회할 수 있어 검색 결과의 신뢰도와 설명력이 향상되었습니다.
